
BeetSql(数据库管理工具)
v3.2.1 官方版大小:19.8 MB 更新:2024/12/21
类别:应用软件系统:WinAll
分类分类
大小:19.8 MB 更新:2024/12/21
类别:应用软件系统:WinAll
BeetSql是一个功能强大、简单易用的数据库管理工具,集Hibernate、Mybatis等多种优点于一身,是一款功能丰富齐全、专业实用的DAO工具,适用于以SQL为中心且又能自动能生成大量常用的SQL的应用,是一款专门针对程序编程、数据库设计的用户而设计研发,非常方便实用;BeetSql这款数据库管理软件,开发效率高、跨多数据库、对DBA友好,同时指出语法高亮、错误提示、模型指出等多种功能,可以帮助用户减少代码数据库代码编辑错误、提高数据库设计和数据库管理效率,是一款不可多得的数据库管理软件。
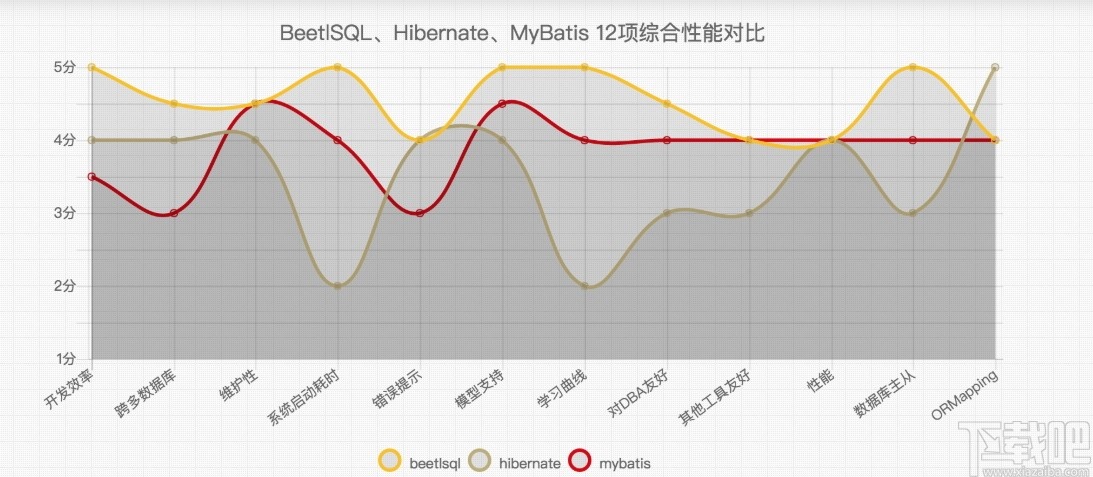
BeetlSQL的目标是提供开发高效,维护高效,运行高效的数据库访问框架,在一个系统多个库的情况下,提供一致的编写代码方式。支持如下数据平台
传统数据库:MySQL,MariaDB,Oralce,Postgres,DB2,SQL Server,H2,SQLite,Derby,神通,达梦,华为高斯,人大金仓,PolarDB等
大数据:HBase,ClickHouse,Cassandar,Hive
物联网时序数据库:Machbase,TD-Engine,IotDB
SQL查询引擎:Drill,Presto,Druid
内存数据库:ignite,CouchBase
BeetlSQL 不仅仅是简单的类似MyBatis或者是Hibernate,或者是俩着的综合,BeetlSQL远大理想是对标甚至超越Spring Data,是实现数据访问统一的框架,无论是传统数据库,还是大数据,还是查询引擎或者时序库,内存数据库。
简单易用
简单易用Beetl类似Javascript语法和习俗,只要半小时就能通过半学半猜完全掌握用法。拒绝其他模板引擎那种非人性化的语法和习俗。同时也能支持html 标签,使得开发CMS系统比较容易
易于整合
Beetl能很容易的与各种web框架整合,如Act Framework,Spring MVC,Struts,Nutz,Jodd,Servlet,JFinal等。支持模板单独开发和测试,即在MVC架构中,即使没有M和C部分,也能开发和测试模板。
性能卓越
Beetl远超过主流java模板引擎性能(引擎性能5-6倍与freemaker,2倍于JSP),宏观上通过了优化的渲染引擎,IO的二进制输出,字节码属性访问增强,微观上通过一维数组保存上下文Context,静态文本合并处理,重复使用字节数组来防止java频繁的创建和销毁数组,还使用模板缓存,运行时优化等方法。
开发效率高
无需注解,自动使用大量内置SQL,轻易完成增删改查功能,节省50%的开发工作量。 数据模型支持Pojo,也支持Map/List这种快速模型,也支持混合模型。 SQL 模板基于Beetl实现,更容易写和调试,以及扩展。 可以针对单个表(或者视图)代码生成pojo类和sql模版,甚至是整个数据库。能减少代码编写工作量。
易于维护SQL
以更简洁的方式,Markdown方式集中管理,同时方便程序开发和数据库SQL调试。可以自动将sql文件映射为dao接口类。灵活直观的支持支持一对一,一对多,多对多关系映射而不引入复杂的OR Mapping概念和技术。具备Interceptor功能,可以调试,性能诊断SQL,以及扩展其他功能
其他特色
内置支持主从数据库支持的开源工具,支持跨数据库平台,开发者所需工作减少到最小,目前跨数据库支持MySql、Postgres、Oracle、SQLServer、h2、SQLite、DB2、CLickhouse、HBase,Cassandar、Hive、TD-Engine,Drill、Presto、ignite、CouchBase等
com.ibeetl
beetlsql
2.13.0.RELEASE
com.ibeetl
beetl
${最新版本}
或者依次下载beetlsql,beetl 最新版本 包放到classpath里
准备工作为了快速尝试BeetlSQL,需要准备一个Mysql数据库或者其他任何beetlsql支持的数据库,然后执行如下sql脚本
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`create_date` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
编写一个Pojo类,与数据库表对应(或者可以通过SQLManager的gen方法生成此类,参考一下节)
import java.math.*;
import java.util.Date;
/*
*
* gen by beetlsql 2016-01-06
*/
public class User {
private Integer id ;
private Integer age ;
private String name ;
private Date createDate ;
}
主键需要通过注解来说明,如@AutoID,或者@AssignID等,但如果是自增主键,且属性是名字是id,则不需要注解,自动认为是自增主键
代码例子写一个java的Main方法,内容如下
ConnectionSource source = ConnectionSourceHelper.getSimple(driver, url, userName, password);
DBStyle mysql = new MySqlStyle();
// sql语句放在classpagth的/sql 目录下
SQLLoader loader = new ClasspathLoader("/sql");
// 数据库命名跟java命名一样,所以采用DefaultNameConversion,还有一个是UnderlinedNameConversion,下划线风格的,
UnderlinedNameConversion nc = new UnderlinedNameConversion();
// 最后,创建一个SQLManager,DebugInterceptor 不是必须的,但可以通过它查看sql执行情况
SQLManager sqlManager = new SQLManager(mysql,loader,source,nc,new Interceptor[]{new DebugInterceptor()});
//使用内置的生成的sql 新增用户,如果需要获取主键,可以传入KeyHolder
User user = new User();
user.setAge(19);
user.setName("xiandafu");
sqlManager.insert(user);
//使用内置sql查询用户
int id = 1;
user = sqlManager.unique(User.class,id);
//模板更新,仅仅根据id更新值不为null的列
User newUser = new User();
newUser.setId(1);
newUser.setAge(20);
sqlManager.updateTemplateById(newUser);
//模板查询
User query = new User();
query.setName("xiandafu");
List list = sqlManager.template(query);
//Query查询
Query userQuery = sqlManager.getQuery(User.class);
List users = userQuery.lambda().andEq(User::getName,"xiandafy").select();
//使用user.md 文件里的select语句,参考下一节。
User query2 = new User();
query.setName("xiandafu");
List list2 = sqlManager.select("user.select",User.class,query2);
// 这一部分需要参考mapper一章
UserDao dao = sqlManager.getMapper(UserDao.class);
List list3 = dao.select(query2);
BeetlSql2.8.11 提供了 SQLManagerBuilder来链式创建SQLManager
SQL文件例子通常一个项目还是有少量复杂sql,可能只有5,6行,也可能有上百行,放在单独的sql文件里更容易编写和维护,为了能执行上例的user.select,需要在classpath里建立一个sql目录(在src目录下建立一个sql目录,或者maven工程的resources目录。ClasspathLoader 配置成sql目录,参考上一节ClasspathLoader初始化的代码)以及下面的user.md 文件,内容如下
select
===
select * from user where 1=1
@if(!isEmpty(age)){
and age = #age#
@}
@if(!isEmpty(name)){
and name = #name#
@}
关于如何写sql模板,会稍后章节说明,如下是一些简单说明。
采用md格式,===上面是sql语句在本文件里的唯一标示,下面则是sql语句。
@ 和回车符号是定界符号,可以在里面写beetl语句。
"#" 是占位符号,生成sql语句得时候,将输出?,如果你想输出表达式值,需要用text函数,或者任何以db开头的函数,引擎则认为是直接输出文本。
isEmpty是beetl的一个函数,用来判断变量是否为空或者是否不存在.
文件名约定为类名,首字母小写。
sql模板采用beetl原因是因为beetl 语法类似js,且对模板渲染做了特定优化,相比于mybatis,更加容易掌握和功能强大,可读性更好,也容易在java和数据库之间迁移sql语句
注意:sqlId 到sql文件的映射是通过类SQLIdNameConversion来完成的,默认提供了DefaultSQLIdNameConversion实现,即 以 "." 区分最后一部分是sql片段名字,前面转为为文件相对路径,如sqlId是user.select,则select是sql片段名字,user是文件名,beetlsql会在根目录下寻找/user.sql,/user.md ,也会找数据库方言目录下寻找,比如如果使用了mysql数据库,则优先寻找/mysql/user.md,/mysql/user.sql 然后在找/user.md,/user.sql.
如果sql是 test.user.select,则会在/test/user.md(sql) 或者 /mysql/test/user.md(sql) 下寻找“select”片段
代码&sql生成User类并非需要自己写,好的实践是可以在项目中专门写个类用来辅助生成pojo和sql片段,代码如下
public static void main(String[] args){
SqlManager sqlManager = ...... //同上面的例子
sqlManager.genPojoCodeToConsole("user");
sqlManager.genSQLTemplateToConsole("user");
}
注意:我经常在我的项目里写一个这样的辅助类,用来根据表或者视图生成各种代码和sql片段,以快速开发.
genPojoCodeToConsole 方法可以根据数据库表生成相应的Pojo代码,输出到控制台,开发者可以根据这些代码创建相应的类,如上例子,控制台将输出
package com.test;
import java.math.*;
import java.util.Date;
import java.sql.Timestamp;
/*
*
* gen by beetlsql 2016-01-06
*/
public class User {
private Integer id ;
private Integer age ;
private String name ;
private Date createDate ;
}
注意生成属性的时候,id总是在前面,后面依次是类型为Integer的类型,最后面是日期类型,剩下的按照字母排序放到中间。
一旦有了User 类,如果你需要写sql语句,那么genSQLTemplateToConsole 将是个很好的辅助方法,可以输出一系列sql语句片段,你同样可以赋值粘贴到代码或者sql模板文件里(user.md),如上例所述,当调用genSQLTemplateToConsole的时候,生成如下
sample
===
* 注释
select #use("cols")# from user where #use("condition")#
cols
===
id,name,age,create_date
updateSample
===
`id`=#id#,`name`=#name#,`age`=#age#,`create_date`=#date#
condition
===
1 = 1
@if(!isEmpty(name)){
and `name`=#name#
@}
@if(!isEmpty(age)){
and `age`=#age#
@}
beetlsql生成了用于查询,更新,条件的sql片段和一个简单例子。你可以按照你的需要copy到sql模板文件里.实际上,如果你熟悉gen方法,你可以直接gen代码和sql到你的工程里,甚至是整个数据库都可以调用genAll来一次生成
注意sql 片段的生成顺序按照数据库表定义的顺序显示
BeetlSQL 说明获得SQLManagerSQLManager 是系统的核心,他提供了所有的dao方法。获得SQLManager,可以直接构造SQLManager.并通过单例获取如:
ConnectionSource source = ConnectionSourceHelper.getSimple(driver, url, "", userName, password);
DBStyle mysql = new MySqlStyle();
// sql语句放在classpagth的/sql 目录下
SQLLoader loader = new ClasspathLoader("/sql");
// 数据库命名跟java命名一样,所以采用DefaultNameConversion,还有一个是UnderlinedNameConversion,下划线风格的
UnderlinedNameConversion nc = new UnderlinedNameConversion();
// 最后,创建一个SQLManager,DebugInterceptor 不是必须的,但可以通过它查看sql执行情况
SQLManager sqlManager = new SQLManager(mysql,loader,source,nc,new Interceptor[]{new DebugInterceptor()});
更常见的是,已经有了DataSource,创建ConnectionSource 可以采用如下代码
ConnectionSource source = ConnectionSourceHelper.getSingle(datasource);
如果是主从Datasource
ConnectionSource source = ConnectionSourceHelper.getMasterSlave(master,slaves)
关于使用Sharding-JDBC实现分库分表,参考主从一章
查询API简单查询(自动生成sql)public T unique(Class clazz,Object pk) 根据主键查询,如果未找到,抛出异常.
public T single(Class clazz,Object pk) 根据主键查询,如果未找到,返回null.
public List all(Class clazz) 查询出所有结果集
public List all(Class clazz, int start, int size) 翻页
public int allCount(Class clazz) 总数
(Query)单表查询SQLManager提供Query类可以实现单表查询操作
SQLManager sql = ...
List list = sql.query(User.class).andEq("name","hi").orderBy("create_date").select();
sql.query(User.class) 返回了Query类用于单表查询
如果是Java8,则可以使用lambda表示列名
List list1 = sql.lambdaQuery(User.class).andEq(User::getName, "hi").orderBy(User::getCreateDate).select();
lamdba()方法返回了一个LamdbaQuery 类,列名支持采用lambda。
关于Query操作的具体用法,请参考25.1节
Query对象通常适合在业务操作中使用,而不能代替通常的前端界面查询,前端界面查询推荐使用sqlId来查询
Query提供俩个静态方法filterEmpty,filterNull,这俩个方法返回StrongValue的子类,当andEq等方法的参数是StrongValue子类的时候,将根据条件拼接SQL语句。StrongValue定义如下
public interface StrongValue {
/**
* value是否是一个有效的值
* 返回false则不进行SQL组装
* @return
*/
boolean isEffective();
/**
* 获取实际的value值
* @return
*/
Object getValue();
}
如下是一个使用例子
Blog blog = query.andEq(Blog::getTitle, Query.filterNull(null))
.andIn(Blog::getId, Arrays.asList(1,2,3,4,5,6,7))
.andNotIn(Blog::getId, Query.filterEmpty(Collections.EMPTY_LIST))
.andNotEq(Blog::getId, Query.filterEmpty(""))
.andLess(Blog::getId, Query.filterEmpty(2))
.andGreatEq(Blog::getId, Query.filterEmpty(0)).single()
template查询public List template(T t) 根据模板查询,返回所有符合这个模板的数据库 同上,mapper可以提供额外的映射,如处理一对多,一对一
public T templateOne(T t) 根据模板查询,返回一条结果,如果没有找到,返回null
public List template(T t,int start,int size) 同上,可以翻页
public long templateCount(T t) 获取符合条件的个数
public List template(Class target,Object paras,long start, long size) 模板查询,参数是paras,可以是Map或者普通对象
public long templateCount(Class target, Object paras) 获取符合条件个数
翻页的start,系统默认位从1开始,为了兼容各个数据库系统,会自动翻译成数据库习俗,比如start为1,会认为mysql,postgres从0开始(从start-1开始),oralce,sqlserver,db2从1开始(start-0)开始。
然而,如果你只用特定数据库,可以按照特定数据库习俗来,比如,你只用mysql,start为0代表起始纪录,需要配置
OFFSET_START_ZERO = true
这样,翻页参数start传入0即可。
模板查询一般时间较为简单的查询,如用户登录验证
User template = new User();
template.setName(...);
template.setPassword(...);
template.setStatus(1);
User user = sqlManager.templateOne(template);
通过sqlid查询,sql语句在md文件里public List select(String sqlId, Class clazz, Map paras) 根据sqlid来查询,参数是个map
public List select(String sqlId, Class clazz, Object paras) 根据sqlid来查询,参数是个pojo
public List select(String sqlId, Class clazz) 根据sqlid来查询,无参数
public T selectSingle(String id,Object paras, Class target) 根据sqlid查询,输入是Pojo,将对应的唯一值映射成指定的target对象,如果未找到,则返回空。需要注意的时候,有时候结果集本身是空,这时候建议使用unique
public T selectSingle(String id,Map paras, Class target) 根据sqlid查询,输入是Map,将对应的唯一值映射成指定的target对象,如果未找到,则返回空。需要注意的时候,有时候结果集本身是空,这时候建议使用unique
public T selectUnique(String id,Object paras, Class target) 根据sqlid查询,输入是Pojo或者Map,将对应的唯一值映射成指定的target对象,如果未找到,则抛出异常
public T selectUnique(String id,Map paras, Class target) 根据sqlid查询,输入是Pojo或者Map,将对应的唯一值映射成指定的target对象,如果未找到,则抛出异常
public Integer intValue(String id,Object paras) 查询结果映射成Integer,如果找不到,返回null,输入是object
public Integer intValue(String id,Map paras) 查询结果映射成Integer,如果找不到,返回null,输入是map,其他还有 longValue,bigDecimalValue
注意,对于Map参数来说,有一个特殊的key叫着_root,它代表了查询根对象,sql语句中未能找到的变量都会在试图从_root 中查找,关于_root对象,可以参考第8章。 在Map中使用_root, 可以混合为sql提供参数
指定范围查询public List select(String sqlId, Class clazz, Map paras, int start, int size), 查询指定范围
public List select(String sqlId, Class clazz, Object paras, int start, int size) ,查询指定范围
beetlsql 默认从1 开始,自动翻译为目标数据库的的起始行,如mysql的0,oracle的1
如果你想从0开始,参考11章,配置beetlsql
翻页查询APIpublic void pageQuery(String sqlId,Class clazz,PageQuery query)
BeetlSQL 提供一个PageQuery对象,用于web应用的翻页查询,BeetlSql假定有sqlId 和sqlId$count,俩个sqlId,并用这来个来翻页和查询结果总数.如:
queryNewUser
===
select * from user order by id desc ;
queryNewUser$count
===
select count(1) from user
对于俩个相似的sql语句,你可以使用use函数,把公共部分提炼出来.
大部分情况下,都不需要2个sql来完成,一个sql也可以,要求使用page函数或者pageTag标签,这样才能同时获得查询结果集总数和当前查询的结果
queryNewUser
===
select
@pageTag(){
a.*,b.name role_name
@}
from user a left join b ...
如上sql,会在pageQuery查询的时候转为俩条sql语句
select count(1) from user a left join b...
select a.*,b.name role_name from user a left join b...
如果字段较多,为了输出方便,也可以使用pageTag,字段较少,用page函数也可以. ,具体参考pageTag和page函数说明.翻页代码如下
//从第一页开始查询,无参数
PageQuery query = new PageQuery();
sql.pageQuery("user.queryNewUser", User.class,query);
System.out.println(query.getTotalPage());
System.out.println(query.getTotalRow());
System.out.println(query.getPageNumber());
List list = query.getList();
PageQuery 对象也提供了 orderBy属性,用于数据库排序,如 "id desc"
跨数据库支持如果你打算使用PageQuery做翻页,且只想提供一个sql语句+page函数,那考虑到跨数据库,应该不要在这个sql语句里包含排序,因为大部分数据库都不支持. page函数生成的查询总数sql语句,因为包含了oder by,在大部分数据库都是会报错的的,比如:select count(1) form user order by name,在sqlserver,mysql,postgresql都会出错,oracle允许这种情况, 因此,如果你要使用一条sql语句+page函数,建议排序用PageQuery对象里有排序属性oderBy,可用于排序,而不是放在sql语句里.
2.8版本以后也提供了标签函数 pageIgnoreTag,可以用在翻页查询里,当查询用作统计总数的时候,会忽略标签体内容,如
select page("*") from xxx
@pageIgnoreTag(){
order by id
@}
如上语句,在求总数的时候,会翻译成 select count(1) from xxx
如果你不打算使用PageQuery+一条sql的方式,而是用两条sql来分别翻页查询和统计总数,那无所谓
或者你直接使用select 带有起始和读取总数的接口,也没有关系,可以在sql语句里包含排序
如果PageQuery对象的totalRow属性大于等于0,则表示已经知道总数,则不会在进行求总数查询
更新API添加,删除和更新均使用下面的API
自动生成sqlpublic void insert(Object paras) 插入paras到paras关联的表
public void insert(Object paras,boolean autoAssignKey) 插入paras到paras对象关联的表,并且指定是否自动将数据库主键赋值到paras里,适用于对于自增或者序列类数据库产生的主健
public void insertTemplate(Object paras) 插入paras到paras关联的表,忽略为null值或者为空值的属性
public void insertTemplate(Object paras,boolean autoAssignKey) 插入paras到paras对象关联的表,并且指定是否自动将数据库主键赋值到paras里,忽略为null值或者为空值的属性,调用此方法,对应的数据库必须主键自增。
public void insert(Class clazz,Object paras) 插入paras到clazz关联的表
public void insert(Class clazz,Object paras,KeyHolder holder),插入paras到clazz关联的表,如果需要主键,可以通过holder的getKey来获取,调用此方法,对应的数据库必须主键自增
public int insert(Class clazz,Object paras,boolean autoAssignKey) 插入paras到clazz关联的表,并且指定是否自动将数据库主键赋值到paras里,调用此方法,对应的数据库必须主键自增。
public int updateById(Object obj) 根据主键更新,所有值参与更新
public int updateTemplateById(Object obj) 根据主键更新,属性为null的不会更新
public int updateBatchTemplateById(Class clazz,List list) 批量根据主键更新,属性为null的不会更新
public int updateTemplateById(Class clazz,Map paras) 根据主键更新,组件通过clazz的annotation表示,如果没有,则认为属性id是主键,属性为null的不会更新。
public int[] updateByIdBatch(List list) 批量更新
public void insertBatch(Class clazz,List list) 批量插入数据
public void insertBatch(Class clazz,List list,boolean autoAssignKey) 批量插入数据,如果数据库自增主键,获取。
public int upsert(Object obj), 更新或者插入一条。先判断是否主键为空,如果为空,则插入,如果不为空,则从数据库 按照此主健取出一条,如果未取到,则插入一条,其他情况按照主键更新。插入后的自增或者序列主健
int upsertByTemplate(Object obj) 同上,按照模板插入或者更新。
通过sqlid更新(删除)public int insert(String sqlId,Object paras,KeyHolder holder) 根据sqlId 插入,并返回主键,主键id由paras对象所指定,调用此方法,对应的数据库表必须主键自增。
public int insert(String sqlId,Object paras,KeyHolder holder,String keyName) 同上,主键由keyName指定
public int insert(String sqlId,Map paras,KeyHolder holder,String keyName),同上,参数通过map提供
public int update(String sqlId, Object obj) 根据sqlid更新
public int update(String sqlId, Map paras) 根据sqlid更新,输出参数是map
public int[] updateBatch(String sqlId,List list) 批量更新
public int[] updateBatch(String sqlId,Map[] maps) 批量更新,参数是个数组,元素类型是map
直接执行SQL模板直接执行sql模板语句一下接口sql变量是sql模板
public List execute(String sql,Class clazz, Object paras)
public List execute(String sql,Class clazz, Map paras)
public int executeUpdate(String sql,Object paras) 返回成功执行条数
public int executeUpdate(String sql,Map paras) 返回成功执行条数
直接执行JDBC sql语句查询 public List execute(SQLReady p,Class clazz) SQLReady包含了需要执行的sql语句和参数,clazz是查询结果,如
List list = sqlManager.execute(new SQLReady("select * from user where name=? and age = ?","xiandafu",18),User.class);)
public PageQuery execute(SQLReady p, Class clazz, PageQuery pageQuery)
String jdbcSql = " select *from user order by id";
PageQuery query = new PageQuery(1,20);
query = sql.execute(new SQLReady(jdbcSql), User.class, query);
注意:sql参数通过SQLReady 传递,而不是PageQuery。
更新 public int executeUpdate(SQLReady p) SQLReady包含了需要执行的sql语句和参数,返回更新结果
public int[] executeBatchUpdate(SQLBatchReady batch) 批量更新(插入)
直接使用Connection public T executeOnConnection(OnConnection call),使用者需要实现onConnection方法的call方法,如调用存储过程
List users = sql.executeOnConnection(new OnConnection(){
@Override
public List call(Connection conn) throws SQLException {
CallableStatement cstmt = conn.prepareCall("{ ? = call md5( ? ) }");
ResultSet rs = callableStatement.executeQuery();
return this.sqlManagaer.getDefaultBeanProcessors().toBeanList(rs,User.class);
}
});
其他强制使用主或者从如果为SQLManager提供多个数据源,默认第一个为主库,其他为从库,更新语句将使用主库,查询语句使用从库库
可以强制SQLManager 使用主或者从
public void useMaster(DBRunner f) DBRunner里的beetlsql调用将使用主数据库库
public void useSlave(DBRunner f) DBRunner里的beetlsql调用将使用从数据库库
对于通常事务来说只读事务则从库,写操作事务则总是主库。关于主从支持,参考17章
生成Pojo代码和SQ片段用于开发阶段根据表名来生成pojo代码和相应的sql文件
genPojoCodeToConsole(String table), 根据表名生成pojo类,输出到控制台.
genSQLTemplateToConsole(String table),生成查询,条件,更新sql模板,输出到控制台。
genPojoCode(String table,String pkg,String srcPath,GenConfig config) 根据表名,包名,生成路径,还有配置,生成pojo代码
genPojoCode(String table,String pkg,GenConfig config) 同上,生成路径自动是项目src路径,或者src/main/java (如果是maven工程)
genPojoCode(String table,String pkg),同上,采用默认的生成配置
genSQLFile(String table), 同上,但输出到工程,成为一个sql模版,sql模版文件的位置在src目录下,或者src/main/resources(如果是maven)工程.
genALL(String pkg,GenConfig config,GenFilter filter) 生成所有的pojo代码和sql模版,
genBuiltInSqlToConsole(Class z) 根据类来生成内置的增删改查sql语句,并打印到控制台
sql.genAll("com.test", new GenConfig(), new GenFilter(){
public boolean accept(String tableName){
if(tableName.equalsIgnoreCase("user")){
return true;
}else{
return false;
}
// return false
}
});
第一个参数是pojo类包名,GenConfig是生成pojo的配置,GenFilter 是过滤,返回true的才会生成。如果GenFilter为null,则数据库所有表都要生成
警告必须当心覆盖你掉你原来写好的类和方法,不要轻易使用genAll,如果你用了,最好立刻将其注释掉,或者在genFilter写一些逻辑保证不会生成所有的代码好sql模板文件
悲观锁 lockSQLManager 提供如下API实现悲观锁,clazz对应的数据库表,主键为pk的记录实现悲观锁
public T lock(Class clazz, Object pk)
相当于sql语句
select * from xxx where id = ? for update
lock 方法必须用在事务环境里才能生效。事务结束后,自动释放
语音计算器 应用软件742 KB3.1.2.1 绿色版
详情RedCrab 应用软件4.83 MB5.1.3.0 免费版
详情Kalkules 应用软件5.07 MB1.9.6.25 绿色版
详情绩点计算器 应用软件52 KB1.01 绿色版
详情F5计算器 应用软件1.3 MB1.2 绿色版
详情MTzone桌面计算器 应用软件913 KB5.2.251 绿色版
详情三角函数计算器绿色版 应用软件209 KB绿色版
详情汽车保险计算器 应用软件323 KB1.0 绿色版
详情社保计算器2015 应用软件323 MB1.0 绿色版
详情孕产期计算器 应用软件593 KB1.0 免费版
详情装修预算软件 应用软件1.95 MB1.01 官方版
详情行列式计算器 应用软件739 KB1.0 免费版
详情行列式计算器 应用软件106 KB2.0 免费版
详情个人所得税计算器 应用软件125 KB1.1 绿色版
详情油耗计算器 应用软件96 KB1.4 绿色版
详情勇芳新计算器 应用软件1.94 MB3.5.275 绿色版
详情数学计算器 应用软件546 KB1.7.3.0 绿色版
详情Microsoft Mathematics 应用软件17.36 MB4.0 免费版
详情少儿算数大师 应用软件770 KB1.5 免费版
详情小计算器 应用软件47 KB1.0 官方版
详情点击查看更多
Bluefish 应用软件4.3 MB2.2.7 中文版
详情阿拉丁增值税计算器 应用软件44 KB10.918 官方版
详情数码照片打印尺寸计算器 应用软件31 KB1.0.0 官方版
详情定时器计算器 应用软件9 KB1.0 官方版
详情一键一家装修自动报价软件 应用软件3.03 MB1.05 官方版
详情使新多功能计算器 应用软件377 KB2.0 官方版
详情茗雅语音计算器 应用软件331 KB2.0 官方版
详情统计初步计算器 应用软件14 KB1.0.0 官方版
详情胎儿体重计算器 应用软件10 KB2012 官方版
详情饮羽桥梁计算器 应用软件6.7 MB1.0.0 官方版
详情语音计算器 应用软件742 KB3.1.2.1 绿色版
详情Coco Calculator 应用软件1.8 MB3.0 官方版
详情空调水管保温厚度计算器 应用软件10 KB1.0 官方版
详情简易算式运算器 应用软件249 KB1.1 官方版
详情利息计算器 应用软件359 KB5.00 官方版
详情奇瑞汽车VIN码转PIN码计算器 应用软件357 KB1.1 官方版
详情check sum calculator 应用软件259 KB1.0.1 官方版
详情电线电缆含铜量计算 应用软件34 KB1.0 官方版
详情小蔡计算器 应用软件184 KB3.0 官方版
详情服装多功能计算器 应用软件327 KB1.0 官方版
详情点击查看更多
ky棋牌苹果版本 休闲益智61.5MBv7.2.0
详情禅游斗地主下载抖音 休闲益智61.5MBv7.2.0
详情888彩票网 生活服务33.2MBv9.9.9
详情贪玩娱乐苹果官方下载 休闲益智0MBv7.2.0
详情王者棋牌cc老版本 休闲益智61.5MBv7.2.0
详情彩虹多多专享版 生活服务33.2MBv9.9.9
详情老式水果机 休闲益智0MBv1.0
详情狂暴捕鱼官网504.1 休闲益智61.5MBv7.2.0
详情狂暴捕鱼官网504.1版 休闲益智61.5MBv7.2.0
详情狂暴捕鱼官网有330.3版本 休闲益智61.5MBv7.2.0
详情炸金花下载官方下载 休闲益智61.5MBv7.2.0
详情牛牛下载金币版苹果 休闲益智61.5MBv7.2.0
详情777水果机免费单机版 休闲益智0MBv1.0
详情彩虹多多彩票正版 生活服务33.2MBv9.9.9
详情水果机游戏单机 休闲益智0MBv1.0
详情琼崖海南麻将15旧版下载 休闲益智61.5MBv7.2.0
详情波克城市棋牌 休闲益智61.5MBv7.2.0
详情琼星海南麻将官方下载安装2024 休闲益智61.5MBv7.2.0
详情森林舞会飞禽走兽 休闲益智0MBv1.0
详情王道棋牌官网最新版 休闲益智61.5MBv7.2.0
详情点击查看更多






































