
CTspider(长腿蜘蛛采集插件)
v2.5 官方版大小:2.73 MB 更新:2024/12/03
类别:网络软件系统:WinAll
分类分类
大小:2.73 MB 更新:2024/12/03
类别:网络软件系统:WinAll
CTspider是一款全自动的爬虫插件工具,通过使用这款插件帮助用户在网站中爬取文章数据进行发布,用户的工作效率将会大大的提升;该插件支持几乎所有的平台网站,使用方式也比较简单,只需要用户设置一个定向的采集网址就可以开始针对该网址进行内容采集,并且通过CSS选择器来设置识别采集区域,用户可以轻松选择采集的内容,可以获取网页中的文章摘要,TAG,缩略图等等;这款工具从采集到发布会全自动完成,抓取内容之后程序会对文章进行去重处理,然后再更新发布,在整个过程中基本不需要用户干预。
1、支持内容CSS选择器定向删除和索引删除。
2、支持HTML标签定向过滤和索引过滤。
3、支持HTML属性过滤,以保障内容更加纯净。
4、支持特例标签设置,让用户可以设置直观的参考案例。
5、内容替换模块,帮助用户快速的完成内容文字替换。
6、支持标题关键字替换,将文章标题的关键字快速的替换成其它内容。
7、支持标题或内容前后插入自定义文本,用户可以在插入的文本中编辑任何内容。
1、多任务URL采集,让用户更加高效的完成工作收集信息等。
2、采用定位更加准确的区域选择器,让您采集的内容更精准。
3、列表缩略图采集,软件可以采集列表中的缩略图片并保存。
4、用户完全可以设置相关参数,自定义缩略图的采集属性。
5、支持用户自定义添加网站来源以及网址的字段。
6、支持自动采集列表动态的渲染。
直接安装即可使用,需要授权可以安装下面的步骤进行授权操作。
1、登录长腿蜘蛛-CTspider官网并注册账号(官网地址:https://www.ctspider.com/)
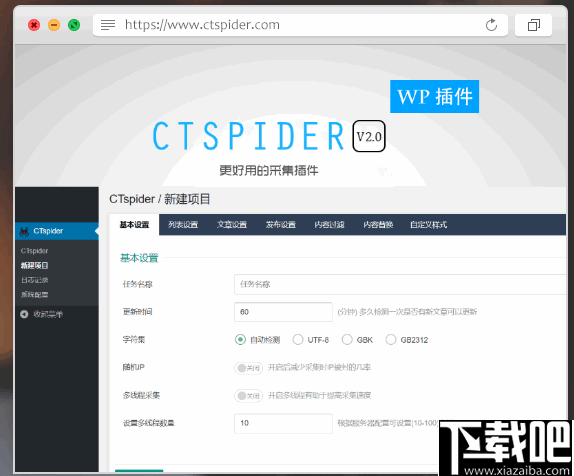
2、填写相关的的注册信息进行注册,邮箱需要填写真实的,便于验证用户。
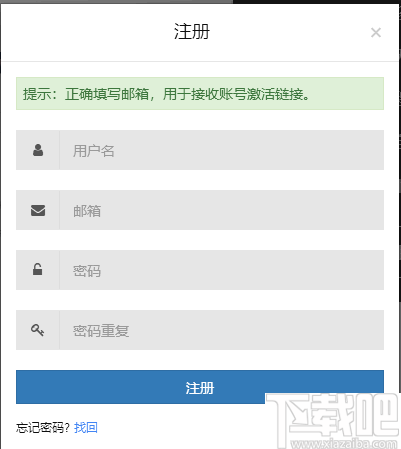
3、登录网站之后,点击用户中心的添加授权域名以获取授权码,每一个用户可以授权三个域名。
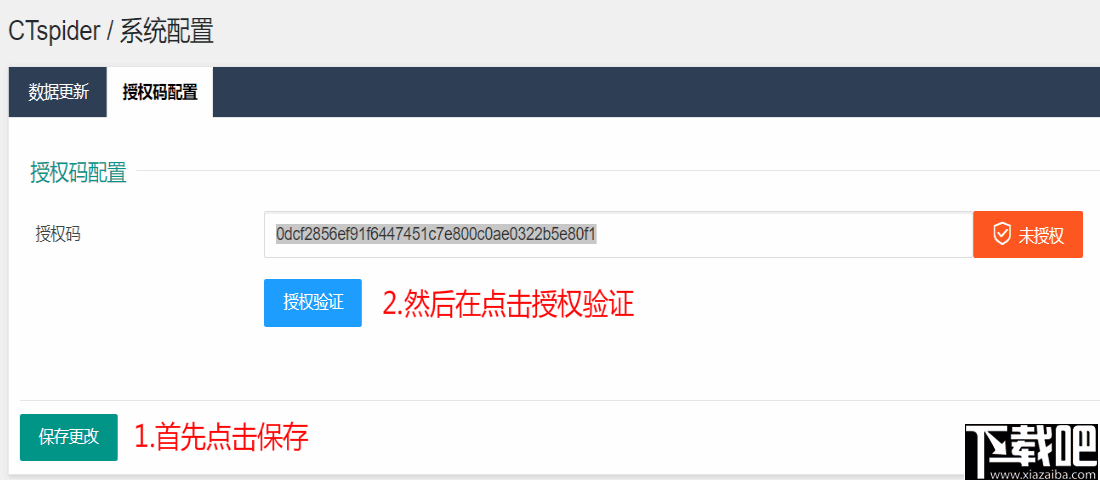
4、获取授权码之后,再按照步骤点击CTspider插件->系统配置->授权码配置->填入授权码->保存配置->验证授权
5、进入下图界面中,将授权码输入到输入框中,然后点击保存,再点击授权验证,现在就完成授权了。
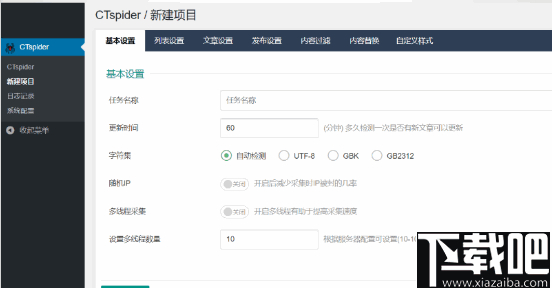
新建项目 / 基本配置
接下来,让我们谈谈如何收集项目
我们以新浪科技为例:
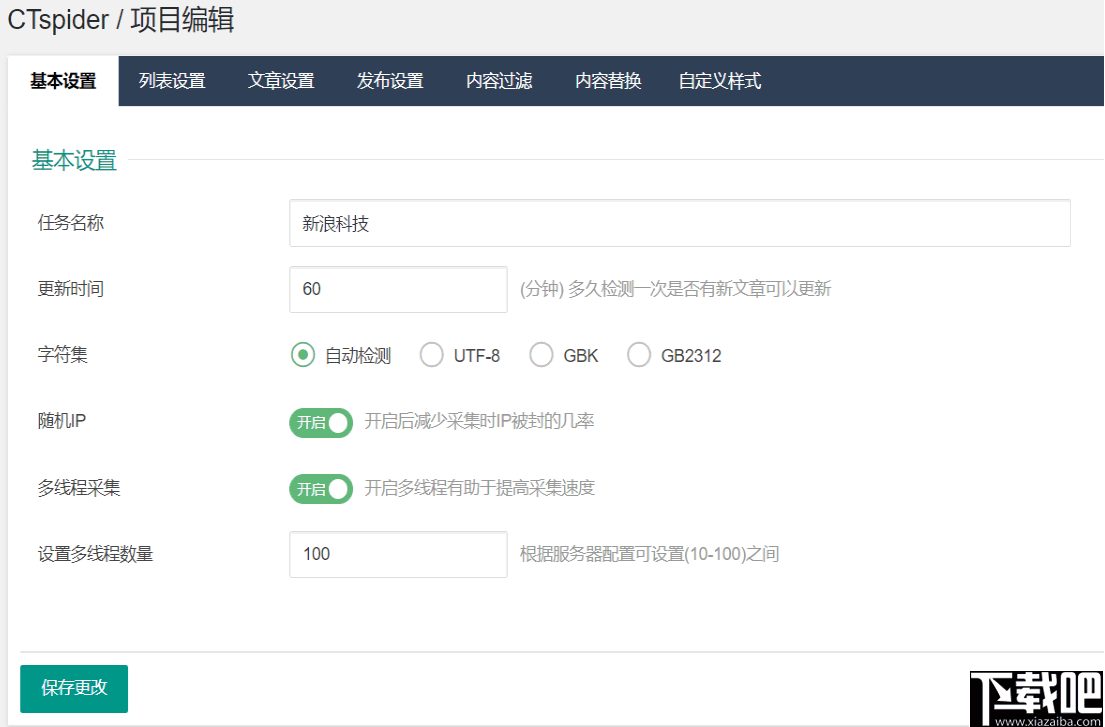
一、基本配置
任务名称:新浪科技(PS:用户定义)
更新时间:默认为60分钟(PS:当前任务每60分钟自动执行一次)
字符集:默认选项为OK(PS:如果代码乱码,请选择当前网页的字符集)
随机IP:开启(PS:打开随机IP将在每次收集IP时自动更改IP,从而降低了阻止服务器IP的可能性)
多线程采集:打开(PS:打开后可以提高采集速度)
多线程数:默认情况下为10(PS:根据您自己的服务器配置使用)、
列表设定
列表URL:http://roll.tech.sina.com.cn/internet_ all / index.shtml(PS:如果需要多个,则可以在新行中添加)
列表区域选择器:。 Contlist> UL> Li(PS:[与CSS选择器完全相同] [可以填充,但不能填充]如果当前页面上有多个相同的列表DOM节点以确保收集的准确性),请右键单击 在Google浏览器中查看元素,您可以看到当前列表数据在下面。 竞争者> UL> Li
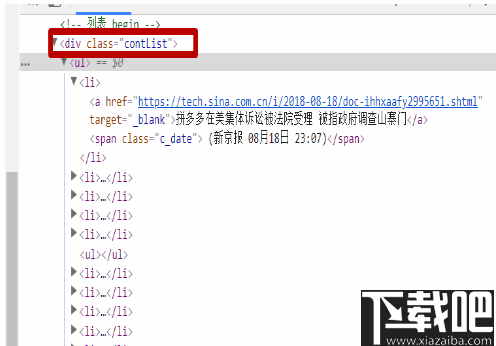
列出缩略图:如果有图片,您可以直接填写当前缩略图CSS选择器
文章URL匹配:a(PS:由于已找到上述区域选择器,因此我们可以直接填写一个标记。如果未找到区域选择器,则将其设置为。根据DOM结构,按Lia或Contlist a。 所收集页面的
将源URL添加到自定义字段:source_ URL(PS:[自定义]可以启用或不启用。设置后,自定义字段源将每天添加到文章中_URL,并将当前收集的URL链接分配给该字段作为前景 调用显示,例如:get_ post_ meta('source_ URL')以调用该字段的值。
单击列表测试以查看当前项目列表配置
点击列表测试可以查看当前项目列表配置情况

文章设置
标题匹配规则:H1
文章内容设置:文章内容
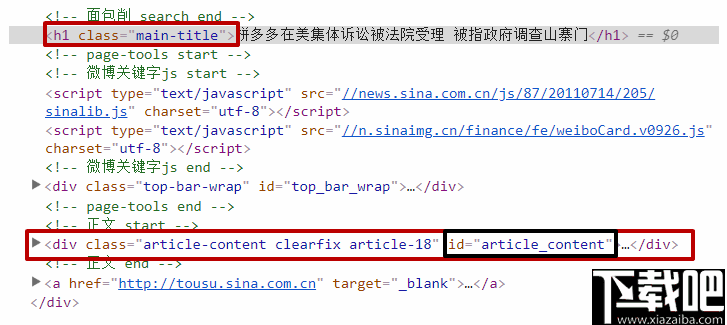
您可以看到标题在H1标签下,或者可以使用。 获得标题的主要标题
正文内容似乎有许多类和IDS。 如果有ID属性,请尝试使用ID。 毕竟,ID是唯一且准确的。
我们还可以添加规则来收集标签
长腿蜘蛛ctspider提供6种通用规则来添加集合,并且可以自定义字段规则(PS:自定义字段规则可以添加多个)
点击获取测试
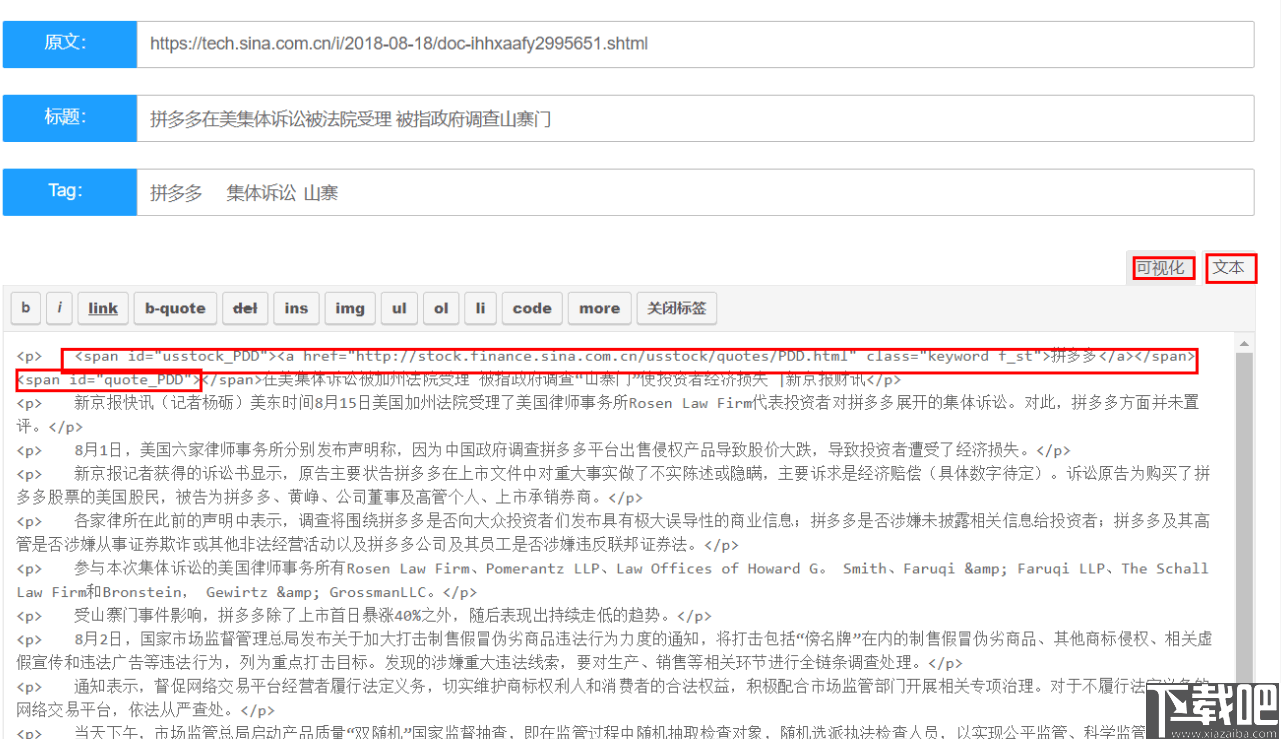
正确显示收集结果(原始文本:标题:标签)
但是,我们发现了一个链接,而不仅仅是一个CSS属性和ID属性,以及一个span标签
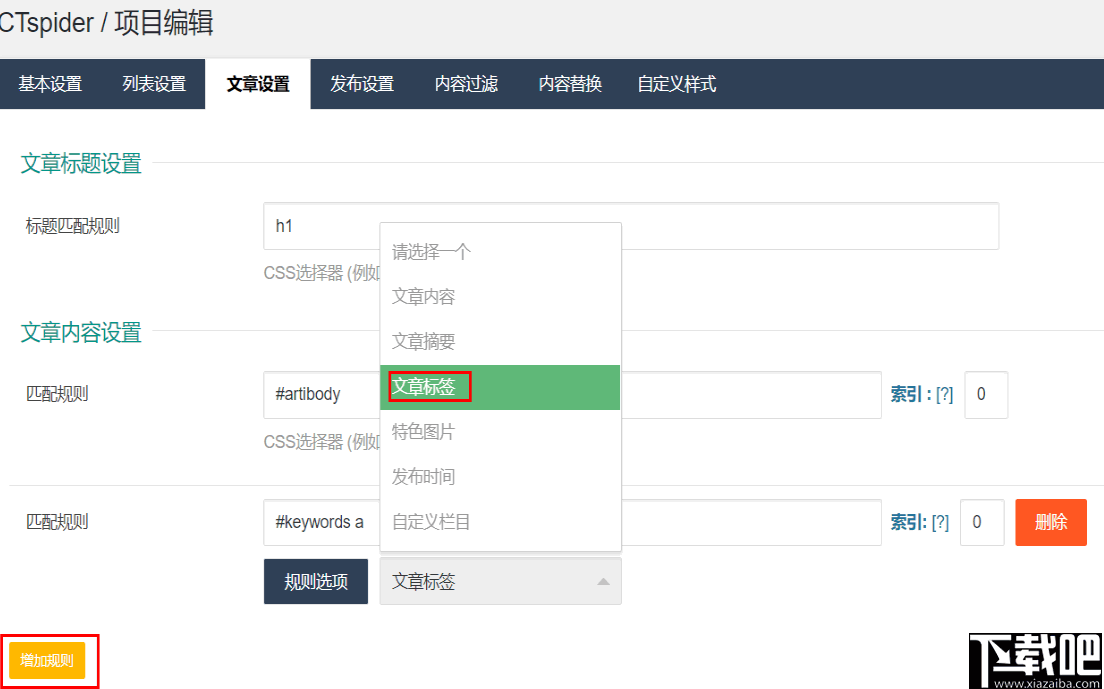
我们可以使用长腿蜘蛛ctspider强大的内容过滤模块进行数据清理
内容过滤
首先,删除数据中的所有链接,但不要删除标签的内容
删除数据中的span标签,而不删除内容
删除数据中无用的类属性和ID属性
具体设置如下:
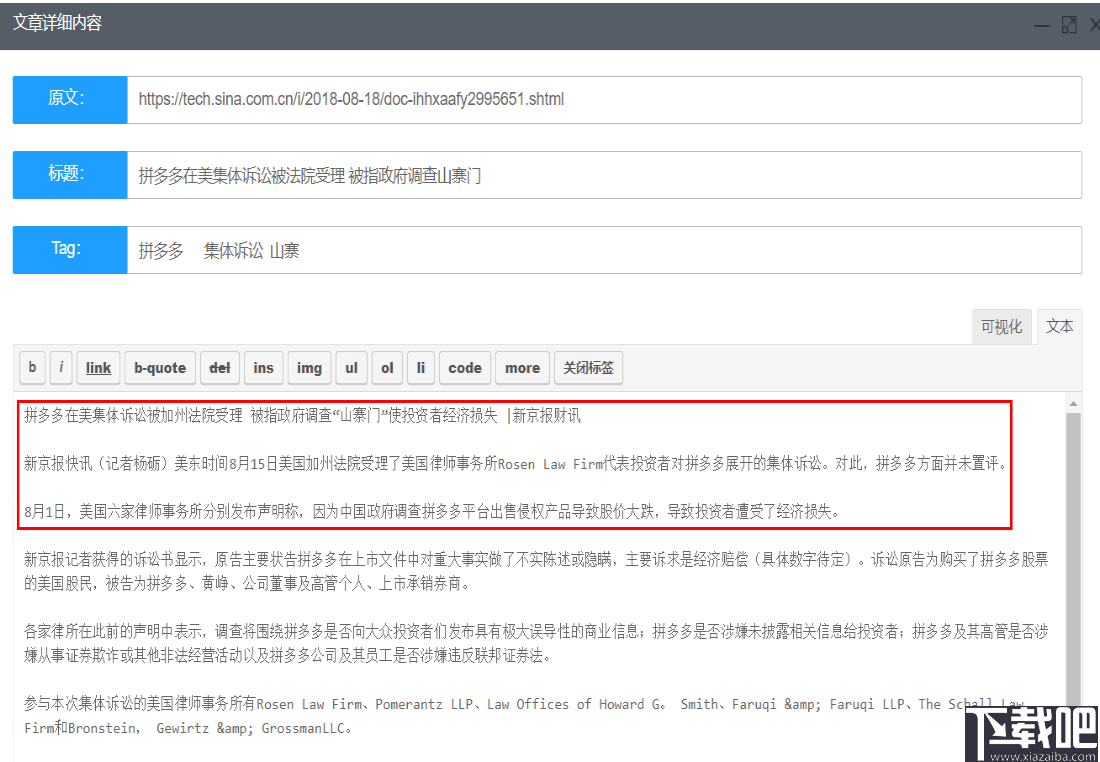
最后,收集并测试数据
Google Hosts更新器 网络软件75 KB3.7.7 绿色版
详情小兵以太网测试仪 网络软件958 KB3.2.7 免费版
详情X-Router 网络软件28.6 MB7.9.5 完整版
详情海拓微信助手 网络软件3.05 MB3.1.90 绿色版
详情css图片抓取大师 网络软件39 KB2.0 绿色版
详情几米一键WiFi共享 网络软件1.44 MB1.0.12.168 官方版
详情Microsoft Silverlight 网络软件6.68 MB5.1.41105.0 官方版
详情微商猎手 网络软件702 KB2.20 免费版
详情广告助手 网络软件4.42 MB1.0.0.6618 官方版
详情Microsoft Silverlight 网络软件12.55 MB5.1.41105.0 官方版
详情Bloxy保护伞广告过滤器 网络软件1.25 MB1.4.3.3 官方版
详情弹窗广告拦截器 网络软件617 KB2.31 绿色版
详情IE修复工具 网络软件1.86 MB1.0 免费版
详情百度客户端 网络软件6.62 MB1.9.0.905 官方版
详情WLAN助手 网络软件3.4 MB1.6.7 免费版
详情AnalogX FastCache 网络软件315 KB1.0.3 免费版
详情360儿童卫士电脑版 网络软件3.6 MB1.0.11.102 官方版
详情胖次百度网盘搜索神器 网络软件34 KB1.4 绿色版
详情广告拦截大师 网络软件2.08 MB2015.9.18.19 官方版
详情菠萝净化大师 网络软件7.16 MB2.2.3 官方版
详情点击查看更多
WIFI万能钥匙电脑版 网络软件10.54 MB2.0.8.0 官方版
详情小鸡快跑盒子 网络软件746 KB1.0 官方版
详情LZZ净网小助手 网络软件485 KB1.2.0 绿色版
详情呱呱助手电脑版 网络软件5.2 MB1.0 官方版
详情局域网一键共享 网络软件269 KB14.3.31 绿色版
详情Fusionzoom Tools 网络软件936 KB1.2 免费版
详情芒果净化大师 网络软件2 MB2.2.4.6 免费版
详情守护童年 网络软件16.75 MB1.1.321.1200 官方版
详情微信自动投票刷票器软件 网络软件585 KB8.2 官方版
详情QQ空间克隆器 网络软件2.02 MB8.2.0.0 安装版
详情搜种神器 网络软件9.55 MB6.4.8 免费版
详情CF活动助手 网络软件1.73 MB2.6.4 免费版
详情猎豹免费wifi 网络软件11.59 MB5.1.9257.1447 官方版
详情品众精准大师 网络软件7.59 MB1.17.922 官方版
详情CV全能通用自动投票机 网络软件578 KB2017 绿色版
详情Cisco Packet Tracer 网络软件55.02 MB6.2 中文版
详情万能网盘搜索器 网络软件2.59 MB6.03 绿色版
详情百度客户端 网络软件6.62 MB1.9.0.905 官方版
详情哔哩哔哩唧唧 网络软件15.56 MB1.208.0 绿色版
详情极速端口扫描器 网络软件687 KB2.0.5 官方版
详情点击查看更多
欢乐拼三张手游专区2025 休闲益智61.5MBv7.2.0
详情爱玩棋牌2025安卓最新版 休闲益智61.5MBv7.2.0
详情六合助手资料下载 生活服务0MBv1.0
详情欢乐拼三张腾讯版2025 休闲益智61.5MBv7.2.0
详情欢乐拼三张腾讯游戏2025 休闲益智61.5MBv7.2.0
详情2025牛牛金花手机棋牌 休闲益智61.5MBv7.2.0
详情欢乐拼三张所有版本2025 休闲益智61.5MBv7.2.0
详情欢乐拼三张手游2025 休闲益智61.5MBv7.2.0
详情35273十年棋牌值得信赖 休闲益智61.5MBv7.2.0
详情欢乐拼三张赢金币2025 休闲益智61.5MBv7.2.0
详情够力七星彩奖表安装 生活服务44MBv3.0.0
详情欢乐拼三张新版app2025 休闲益智61.5MBv7.2.0
详情欢乐拼三张无限金币钻石版2025 休闲益智61.5MBv7.2.0
详情快乐炸翻天免费版 休闲益智0MBv1.0
详情欢乐拼三张微信登录版2025 休闲益智61.5MBv7.2.0
详情jj游戏平台2025 休闲益智61.5MBv7.2.0
详情欢乐拼三张腾讯棋牌2025 休闲益智61.5MBv7.2.0
详情够力排列五奖表旧版 生活服务44MBv3.0.0
详情欢乐拼三张手机版2025 休闲益智61.5MBv7.2.0
详情97棋牌2025官方最新版 休闲益智61.5MBv7.2.0
详情点击查看更多





































