
PDF OCR(文字识别软件)
v4.7.0 官方版大小:55.9 MB 更新:2024/12/13
类别:应用软件系统:WinAll
分类分类
大小:55.9 MB 更新:2024/12/13
类别:应用软件系统:WinAll
PDF OCR是一款国外的PDF识别工具,该工具可以对图像或者PDF纸质文件进行扫描,通过强大的OCR识别技术提取PDF文档中的文字内容,这款工具支持数十个国家的语言,但是唯一的遗憾是在这些语言中不包含中文;这款工具虽然不支持中文界面,但是使用却很简单,即使您不会英文也可以很快上手使用;这款工具可以用于电子书制作或者进行文献识别;不少优秀的文献都来自国外,国内的用户完全可以使用这款工具识别国外的文献内容,然后再通过翻译工具将其翻译成中文;PDF OCR还非常的灵活,您可以指定PDF文档的页面进行识别。
将扫描的PDF转换为文本
PDF OCR将扫描的PDF转换为文本,然后您可以编辑或使用PDF内容。
支持所有页面大小
PDF OCR支持A4,A3,B3,B4,B5和所有其他扫描的页面大小。
将扫描的图像转换为PDF文档
PDF OCR将扫描的图像转换为PDF文档并创建扫描的PDF书籍。
使用方便
PDF OCR只需3次单击即可将PDF转换为文本。
OCR PDF快速
PDF OCR将在45秒内处理10多个页面。
内置文本编辑器
PDF OCR具有内置的文本编辑器,可让您在不使用MS Word或写字板的情况下编辑ocr结果文本。
3种PDF OCR模式
PDF OCR支持3种PDF OCR模式,单页,页面范围和所有页面ocr(批处理)。
支持10+种语言
除英语外,PDF OCR还支持德语,法语,西班牙语,意大利语和其他多种语言。
1、基于强大的OCR识别技术,可以识别图像或者PDF纸质文档中的内容。
2、可以高效的从PDF文档中识别出文字并导出保存为文本。
3、还可以直接在图片中识别图片中的文字,然后将其转换为PDF。
4、高效的转换速度,可以帮助用户高效的完成PDF文档的编辑工作。
5、内置纹文本编辑工具,识别完成之后可以直接在该编辑器中编辑文本。
6、可让您在不使用MS Word的情况下编辑ocr结果文本。
7、用户可以自定义选择需要识别的PDF页码,可以自定义选择多个页面进行批量识别。
8、如果您有多个PDF文件页面,则可以立即将它们转换为可编辑的文本文件。
9、如果您需要创建一本电子数据,那么使用这款工具提取PDF中的内容是非常好的。
10、用户将扫描的PDF文件转换为可编辑的电子文件后,可以继续在软件中进行更正。
11、您可以对A4,A3,B3,B4,B5和其他类型的PDF扫描页进行OCR。
1、启动程序,选择识别模式,左侧是将PDF文件识别成文本,右侧是扫描图像到PDF。

2、这里选择的是将PDF识别成文档,点击之后跳转到此界面中。
3、点击左上角的添加图标,也可以在文件菜单下选择打开选项以进入资源管理器中。
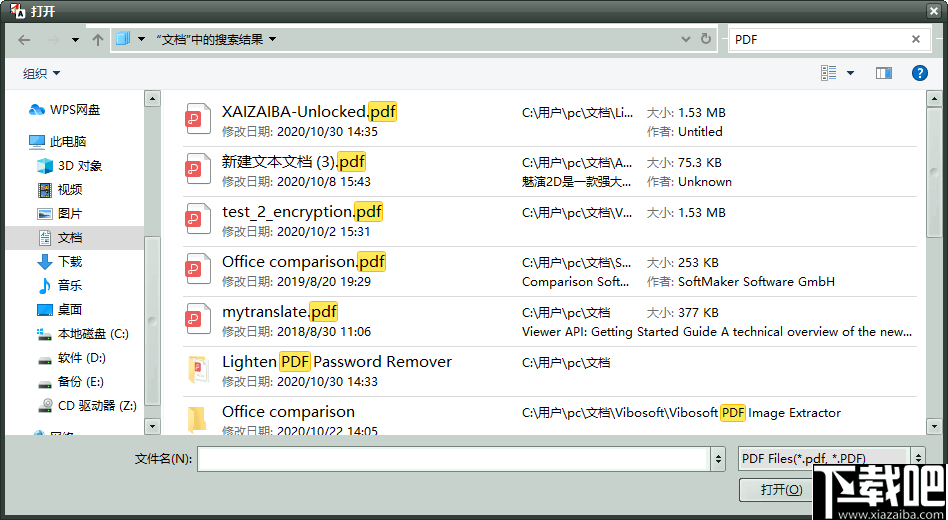
4、在资源管理器中选择您需要进行识别的PDF文档。
5、添加到软件中之后,您可以直观的在软件中查看到PDF的内容。
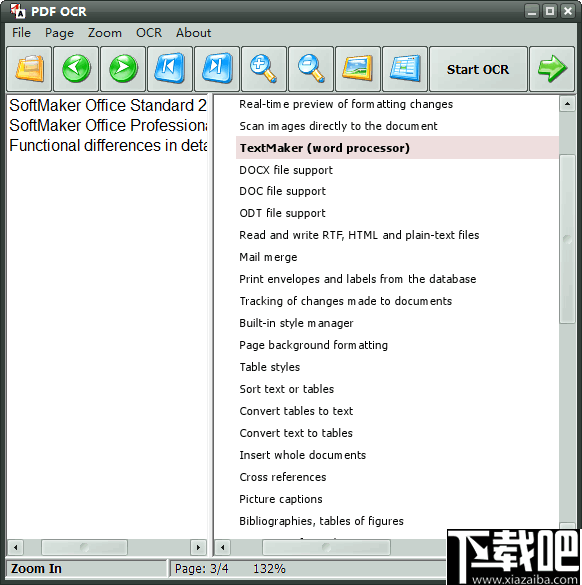
6、您可以通过工具栏中的工具对PDF文档进行翻页和缩放等操作。
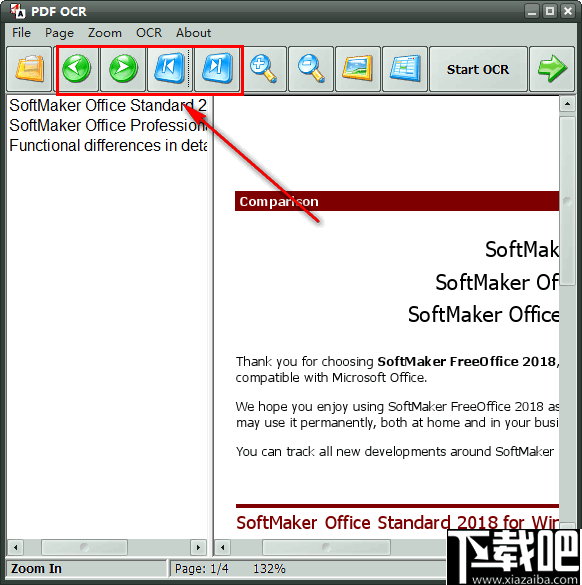
7、点击右上角的“开始OCR”按钮开始进行PDF文档识别。
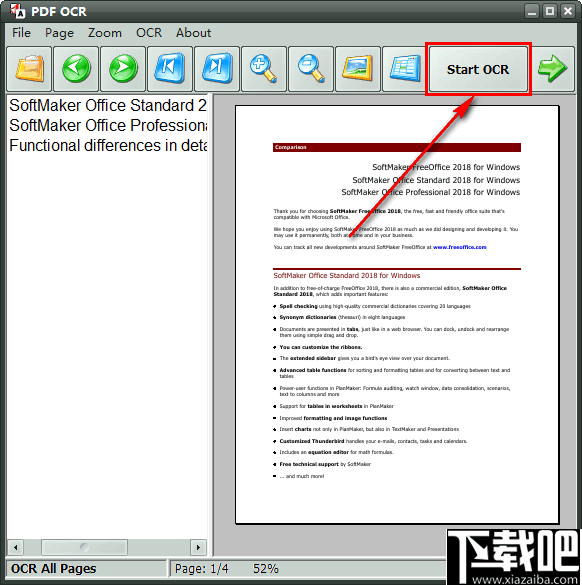
8、打开此面板,在识别之前还需要进行一些简单的设置,比如选择识别的页数。
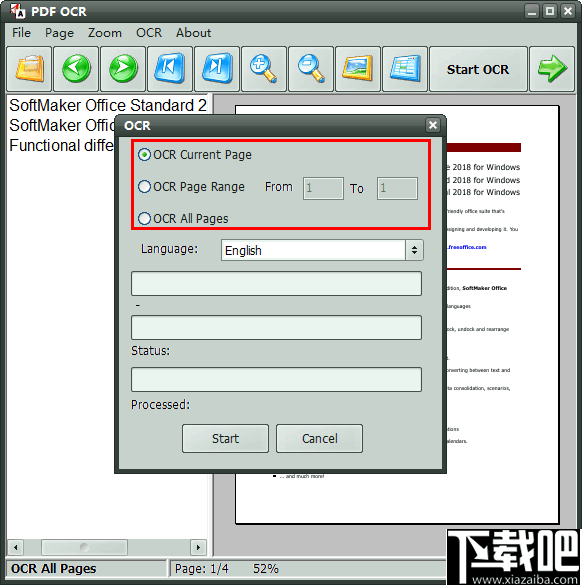
9、然后选择是被识别的文档语言,不支持中文识别,直接选择语言即可。
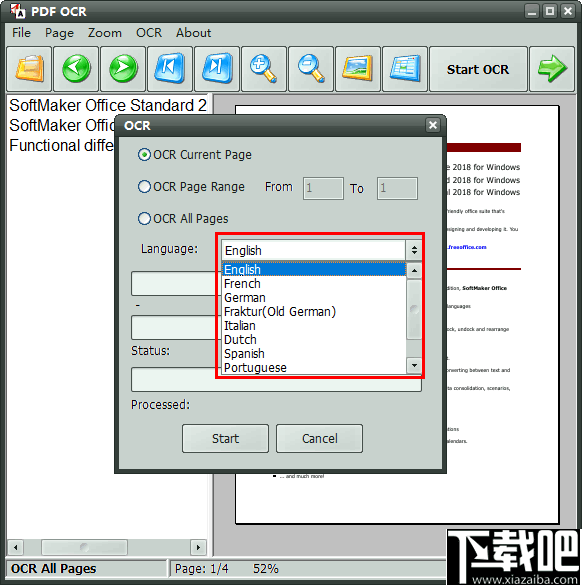
10、接着点击“start”开始是被PDF文档中的文字内容,需要识别的页面越多,花费的时间就相对比较久,三页的PDF内容仅花费了五秒左右的时间。
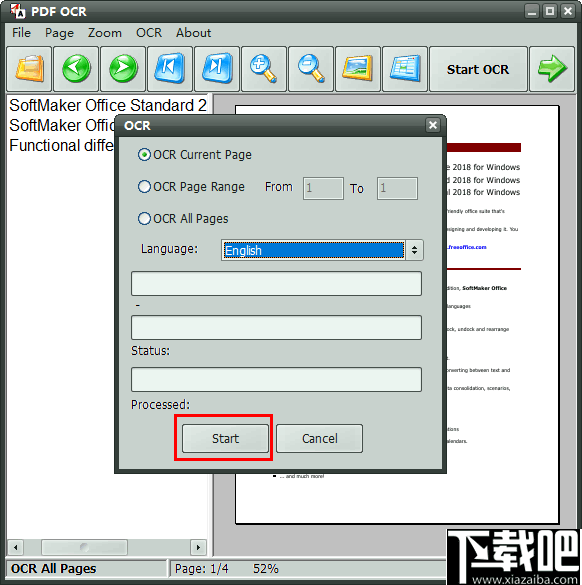
11、识别完成之后,文本内容将自动在此面板中打开,您可以看到内容的标点和段落几乎没有发生改变。
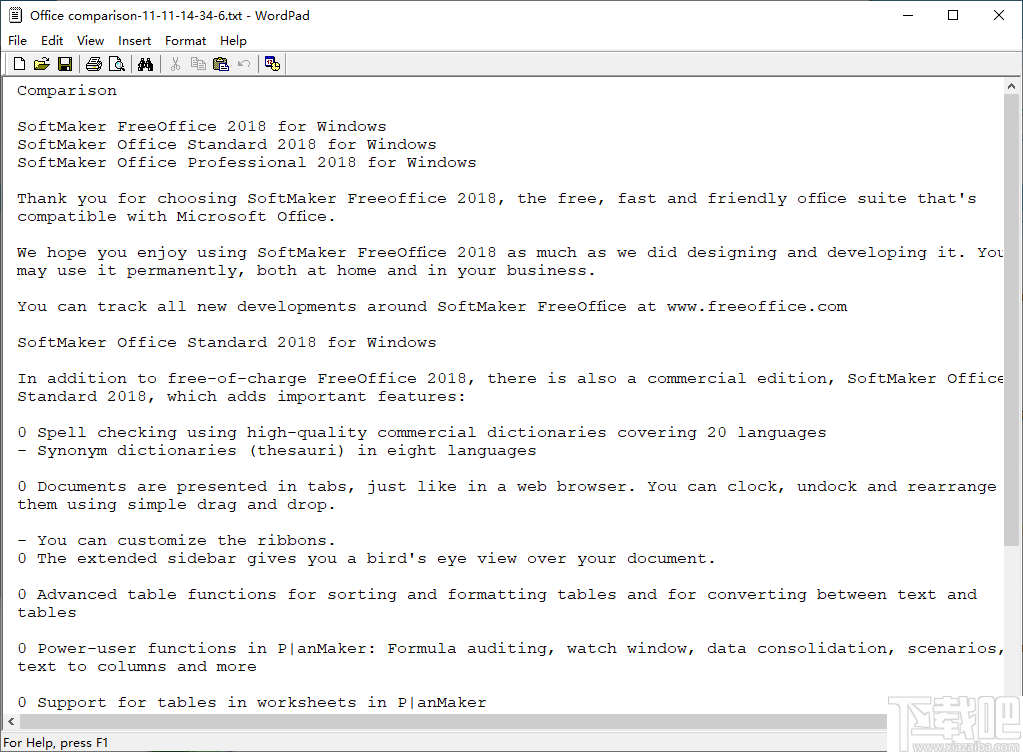
12、直接选中文本右击鼠标,您就可以将其复制到张贴版中等待使用。
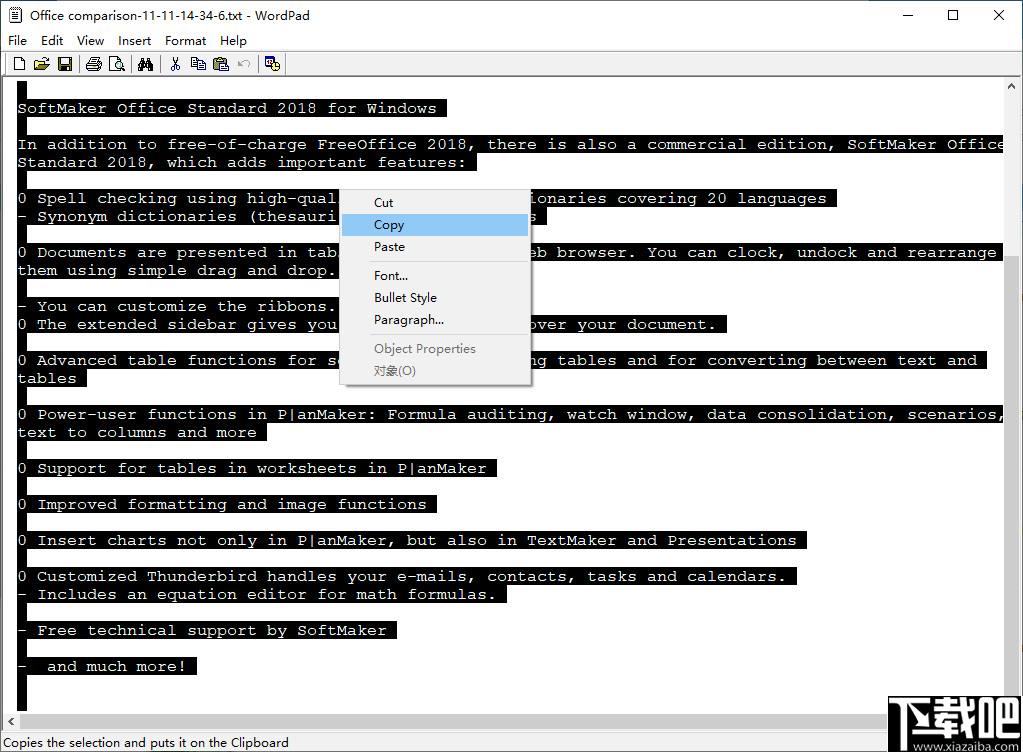
13、您也可以直接将识别出来的内容保存成文本。
第1步-打开PDF文档
单击打开按钮以打开并加载pdf文件,您可以使用绿色和蓝色窄按钮来控制视图,上一页,下一页,第一页和最后一页。
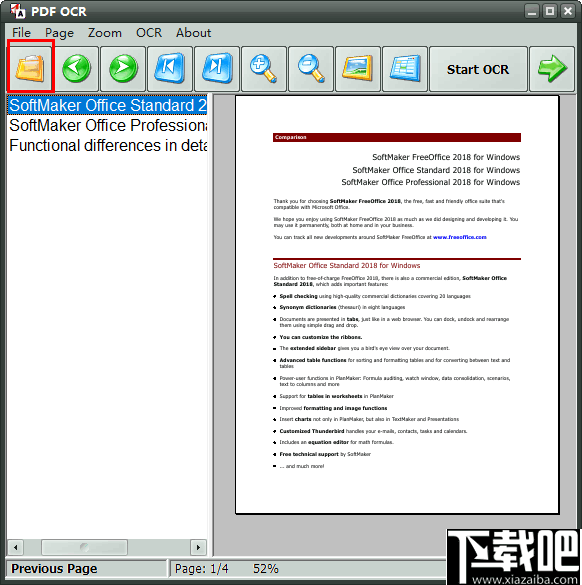
第2步-启动OCR
单击开始OCR按钮,您将看到OCR设置窗口。
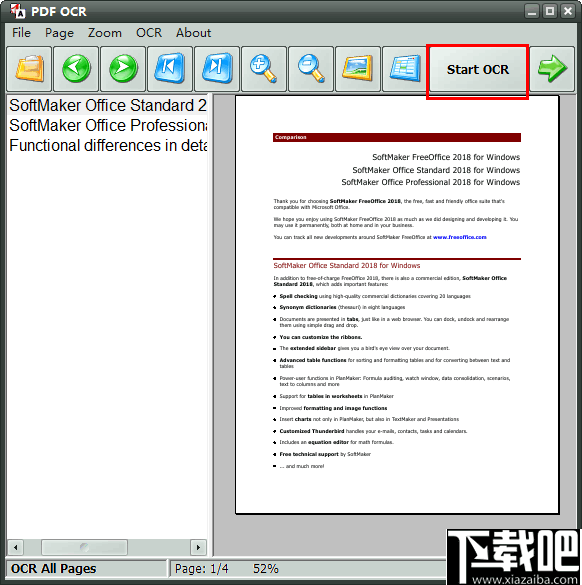
选择一种OCR模式,然后单击“开始”按钮。
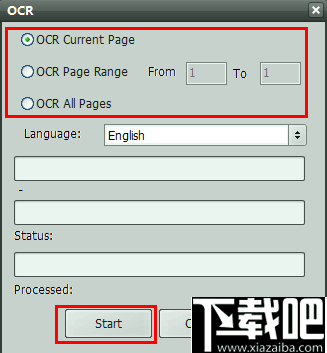
第3步-获得结果
单击“开始”按钮后,请等待几秒钟,然后您将在PDF OCR文本编辑器中看到结果。
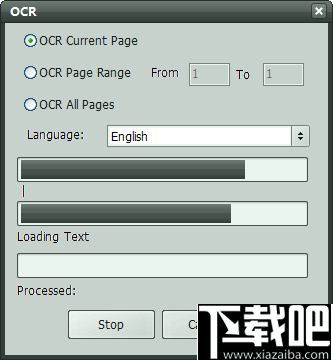
现在,您可以根据需要编辑,复制或保存文本。
什么是PDF OCR,我该怎么办?
PDF OCR基于OCR技术,可将扫描的PDF纸质书和文档快速,轻松地转换为可编辑的电子文本文件。PDF OCR具有内置的文本编辑器,可让您在不使用MS Word的情况下编辑ocr结果文本。PDF OCR还支持批处理模式,一次将所有pdf文件的页面OCR转换为文本。
PDF OCR的系统要求是什么?
Microsoft Windows XP,Windows Vista,Windows 7,Windows 2003,Windows 2000或Windows ME。
奔腾处理器或更高,推荐奔腾4或更高。
128MB RAM或更多,建议使用256MB RAM。
20MB用于安装的硬盘空间。
为什么结果与原始PDF文档不完全相同?
PDF OCR使用光学字符识别技术,该技术可识别图片和图像中的文本,可识别率取决于PDF文本字体,背景和许多因素。因此,PDF OCR无法识别100%正确的文本,但我们仍在努力改善程序。
为什么在结果文本中出现许多未知字符?
PDF OCR只能识别PDF文件中的文本,并且图像和图形也将被识别为文本,因此您可能会得到未知字符。您可以在文本编辑器中删除未知字符。
极速Word 应用软件3.62 MB3.2.8.5 官方版
详情Swiff Saver 应用软件1.7 MB2.4 官方版
详情Swiff Chart Standard 应用软件2.17 MB3.5 标准版
详情Swiff Chart Generator 应用软件1.62 MB3.3.4 官方版
详情新狐电脑传真 应用软件810 KB2.8 官方版
详情91云办公 应用软件22.54 MB2.3.0 官方版
详情Okdo Excel to Word Converter 应用软件4.46 MB5.5 官方版
详情Microsoft Office Excel新增工具集 应用软件2.97 MB2014.09.16 官方版
详情EDraw Soft Diagrammer 应用软件37.05 MB7.9 官方版
详情谷秋精品资源共享课软件 应用软件6.51 MB4.2 简体中文版
详情ROCKOA办公系统 应用软件9.17 MB1.2.3 免费版
详情ExcelPlus 应用软件1.64 MB3.5 官方版
详情赛酷OCR软件 应用软件17.72 MB6.0 免费版
详情OneNote 应用软件442 KB15.0.4689.1000 官方版
详情SmartDraw CI 应用软件164.87 MB22.0.0.8 官方版
详情Authorware 应用软件50.9 MB7.02 官方版
详情Swiff Chart Pro 应用软件2.4 MB3.5 官方版
详情校对助手 应用软件1.42 MB2.0 免费版
详情Microsoft Office Document Imaging 应用软件4.99 MB1.0 简体中文版
详情外贸邮件助手 应用软件510 KB2013.5.21.1 绿色版
详情点击查看更多
迅捷CAD高版本转低版本转换器 应用软件1.15 MB1.0 免费版
详情艾办OA 应用软件132.93 MB1.2.0 官方版
详情10oa协同办公系统 应用软件16.3 MB8.0 免费版
详情米云客服系统 应用软件32.7 MB1.1.3.8 免费版
详情亿图组织结构图 应用软件44 MB8 官方版
详情H3 BPM 应用软件60.75 GB9.2 免费版
详情魔方网表公文管理系统 应用软件274.94 MB1.0 免费版
详情诺言(协同办公平台) 应用软件83.5 MBv1.7.4.11849 免费版
详情全能PDF切割器 应用软件3.69 MB3.1.1 官方版
详情活动运营助手 应用软件8.62 MB1.0 官方版
详情魔方网表物业收费系统 应用软件273 MBV1 官方版
详情魔方网表免费版 应用软件270 MB6.0.0.0047 官方版
详情MAKA(h5制作工具) 应用软件42.8 MBv2.2.3 免费版
详情优企管家 应用软件21.41 MB6.0.9.0 免费版
详情PDF Password Locker & Remover 应用软件17.67 MB3.1.1 免费版
详情快易帮商户管理系统 应用软件57.48 MB1.01 官方版
详情算算量旗舰版免费版 应用软件57.29 MB1.0.21 免费版
详情亿图信息图软件 应用软件237 MB8.7.5 中文版
详情92极呼电话管理系统 应用软件65 MB1.22 免费版
详情优服房屋出租管理软件 应用软件13 MB3.9.18 官方版
详情点击查看更多
宁波游戏大厅手机版2025 休闲益智61.5MBv7.2.0
详情大公鸡七星彩下载 生活服务33.2MBv9.9.9
详情无他棋牌2025版本 休闲益智61.5MBv7.2.0
详情五福彩票2025最新版 生活服务0MBv1.0
详情欢乐拼三张炸金花2025 休闲益智61.5MBv7.2.0
详情欢乐赢三张5.5.0版2025 休闲益智61.5MBv7.2.0
详情王道棋牌2025最新版 休闲益智61.5MBv7.2.0
详情959彩票2025最新版安卓版 生活服务33.1MBv9.9.9
详情彩库宝典下载2025香港 生活服务33.1MBv9.9.9
详情天天电玩城v2.13.6版2025 休闲益智61.5MBv7.2.0
详情水果机单机版无限投币 休闲益智0MBv1.0
详情炸金花游戏免费版手机版 休闲益智61.5MBv7.2.0
详情禅游斗地主2025最新版本 休闲益智61.5MBv7.2.0
详情左右棋牌软件大全2025 休闲益智61.5MBv7.2.0
详情禅游斗地主2025版本 休闲益智61.5MBv7.2.0
详情禅游斗地主无限豆子无限钻石版2025 休闲益智61.5MBv7.2.0
详情JJ斗地主2025最新版 休闲益智61.5MBv7.2.0
详情够力奖表旧版免费下载 生活服务0MBv1.0
详情斗地主赢话费最新版 休闲益智61.5MBv7.2.0
详情欢乐赢三张v2.3.0版2025 休闲益智61.5MBv7.2.0
详情点击查看更多






































