
FlatBuffers(序列化库)
v2.0.0 官方版大小:1.95 MB 更新:2024/06/08
类别:其他软件系统:WinAll
分类分类
大小:1.95 MB 更新:2024/06/08
类别:其他软件系统:WinAll
FlatBuffers是一款非常专业且优秀的跨平台序列化库,旨在最大程度地提高内存效率,适用于多种不同的编程语言,包括C++,C#,C,Java,Python,PHP等,FlatBuffers是一个二进制缓冲区,与大多数内存数据结构不同,FlatBuffers使用严格的对齐和字节顺序规则来确保这些缓冲区是跨平台的,您可以在模式中定义对象类型,也可以将其编译为C++或Java以实现低至零的读写开销,FlatBuffers应用范围非常广,可使用它来序列化游戏数据,也可将其用于客户端与服务器之间的通信,需要的话就赶快下载吧!
编写一个架构文件,该文件可让您定义可能要序列化的数据结构
使用flatc(FlatBuffer编译器)生成带有帮助程序类的C ++头文件(或Java / Kotlin / C#/ Go / Python ..类),以访问和构造序列化数据。
使用FlatBufferBuilder该类构造一个平面二进制缓冲区。生成的函数使您可以递归地将对象添加到此缓冲区中,通常就像进行单个函数调用一样简单。
回读时,您可以从二进制缓冲区中获取指向根对象的指针
可将缓冲区存储或发送到某个地方
对于表对象,FlatBuffers提供了向前/向后兼容性以及字段的一般可选性,以支持大多数形式的格式演变。
FlatBuffers还提供“裸”结构,该结构不提供向前/向后兼容性,但可以更小(对于不太可能更改的非常小的对象(例如坐标对或RGBA颜色)很有用)。
可以将有关格式的大多数信息纳入生成的代码中,从而减少存储数据所需的内存以及访问数据的时间。
在不解析/解包的情况下访问序列化数据
FlatBuffers与众不同之处在于,它在平坦的二进制缓冲区中表示层次结构数据,使得即使不进行解析/解包也可以直接访问分层数据,同时还支持数据结构的演进(forward /向后兼容)。
内存效率和速度
访问数据所需的唯一内存是缓冲区的内存。它需要0个额外的分配(在C ++中,其他语言可能会有所不同)。FlatBuffers也非常适合与mmap(或流)一起使用,仅要求将部分缓冲区存储在内存中。访问仅通过一个额外的间接调用(一种vtable)即可接近原始结构访问的速度,以允许格式演变和可选字段。它针对那些不希望花费时间和空间(许多内存分配)来访问或构造序列化数据的项目,例如在游戏或任何其他对性能敏感的应用程序中。有关详细信息,请参见基准。
灵活
可选字段不仅意味着您具有很好的前后兼容性(对于长寿命游戏也越来越重要:不必使用每个新版本更新所有数据!)。这也意味着您在写入哪些数据,不写入哪些数据以及如何设计数据结构方面有很多选择。
微小的代码占用空间
生成的代码很少,只有一个小的标头作为最小的依赖关系,非常易于集成。同样,请参阅基准测试部分以了解详细信息。
强类型
错误发生在编译时,而不是手动编写重复且容易出错的运行时检查。可以为您生成有用的代码。
使用方便
生成的C ++代码允许简洁的访问和构造代码。然后是可选功能,可以在需要时在运行时高效地解析模式和类似JSON的文本表示形式(比其他JSON解析器更快,更高效地使用内存)。Java,Kotlin和Go代码支持对象重用。C#具有高效的基于结构的访问器。
无需依赖项的跨平台代码
C ++代码可与任何最新的gcc / clang和VS2010一起使用。随附用于测试和示例的构建文件(Android .mk文件,以及用于所有其他平台的cmake)。
编写FlatBuffer模式
要开始使用FlatBuffers,首先需要创建一个schema文件,该文件定义要序列化的每个数据结构的格式。这是schema为我们的定义模板的模板:
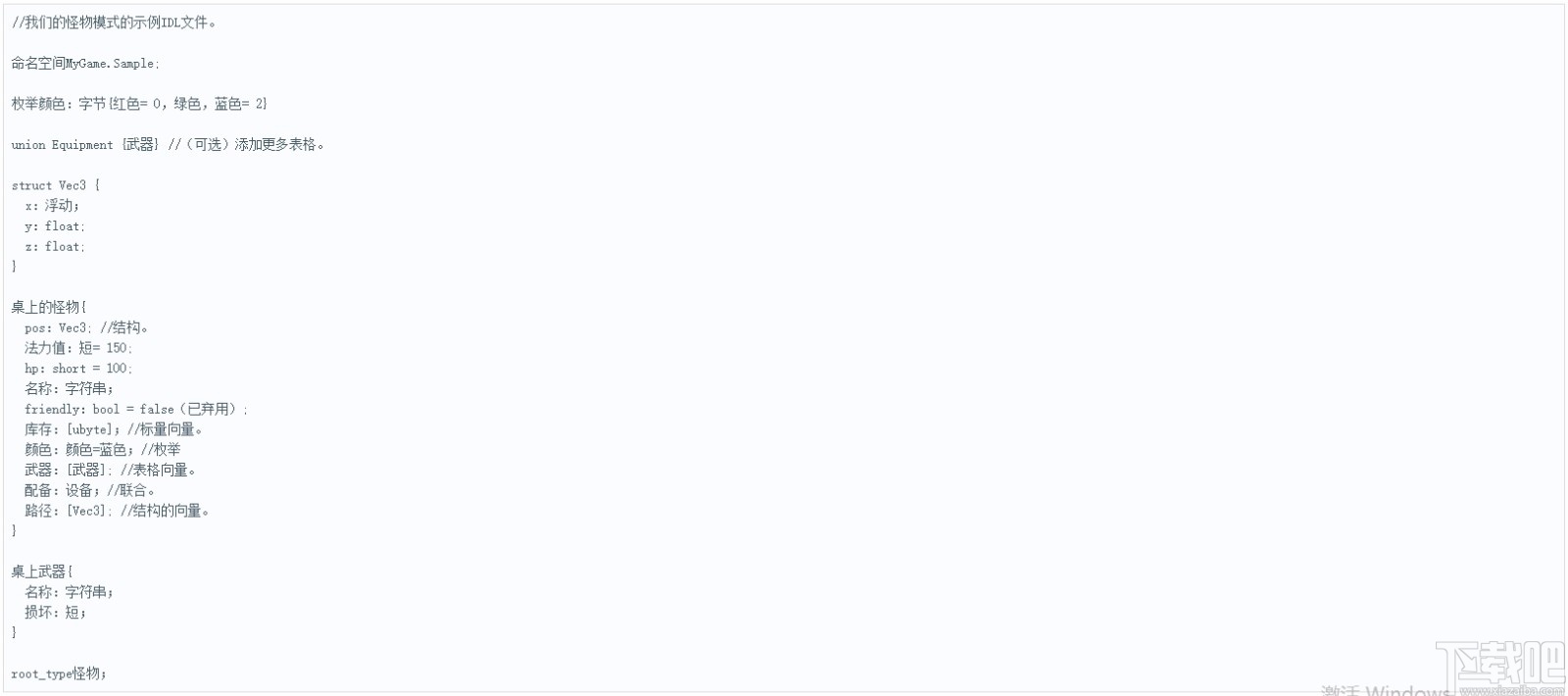
如您所见,schema 接口定义语言(IDL)的语法与C系列语言和其他IDL语言的语法相似。让我们检查其中的每个部分schema以确定其作用。
该schema带开始namespace申报。这将为生成的代码确定相应的包/名称空间。在我们的示例中,我们在Sample名称空间内部具有MyGame名称空间。
接下来,我们有一个enum定义。在此示例中,我们有一个enum类型为byte,名为Color。我们在这三个值enum:Red,Green,和Blue。我们指定Red = 0和Blue = 2,但未指定的显式值Green。由于an的行为enum是在未指定的情况下递增,因此Green将收到的隐式值1。
紧随其后的enum是一个union。在union这个例子不是非常有用,因为它仅包含一个table(命名Weapon)。如果我们创建了多个表,希望union它们能够被引用,则可以向中添加更多元素union Equipment。
之后union是struct Vec3,它表示具有3尺寸的浮点向量。我们使用了struct这里,过了table,因为structs为理想的,不会改变,因为它们使用更少的内存,并具有更快的查找数据结构。
该Monster表是FlatBuffer中的主要对象。这将用作存储我们的orc怪物的模板。我们为字段指定了一些默认值,例如mana:short = 150。如果未指定,则标量字段(如int,uint或float)将默认设置为,0而字符串和表格将默认设置为null。需要注意的另一件事是线路friendly:bool = false (deprecated);。由于您不能从中删除字段table(以支持向后兼容性),因此可以将字段设置为deprecated,这将防止在生成的代码中为此字段生成访问器。deprecated但是,使用时要小心,因为它可能会破坏使用此访问器的旧代码。
该Weapon表是在FlatBuffer中使用的子表。它被使用两次:一次在Monster表中,一次在Equipment联合中。对于我们来说Monster,它用于在我们vector of tables的weapons字段中填充一个via字段Monster。它也是Equipment工会引用的唯一表。
的最后一部分schema是root_type。根类型声明将是序列化数据的根表。在我们的例子中,根类型是我们的Monster表。
标量类型还可以使用别名类型名称,例如int16代替short和float32代替float。因此,我们也可以将该Weapon表编写为:

编译怪物的模式
编写FlatBuffers模式后,下一步就是对其进行编译。
如果您尚未这样做,请按照以下说明来构建flatcFlatBuffer编译器。
一旦flatc构建成功,请为您的语言编译架构:

读写Monster FlatBuffers
现在,我们已经为编程语言编译了架构,我们可以开始创建一些怪物,然后从FlatBuffers对其进行序列化/反序列化。
创建和编写Orc FlatBuffers
第一步是导入/包括库,生成的文件等。

现在我们准备开始构建一些缓冲区。为了开始,我们需要创建一个实例,该实例FlatBufferBuilder将包含缓冲区的增长。您可以传递缓冲区的初始大小(此处为1024字节),如果需要,该大小将自动增长:

创建完之后builder,我们就可以开始序列化数据了。在制作orc怪物之前,让我们创建一些Weapon:aSword和an Axe。

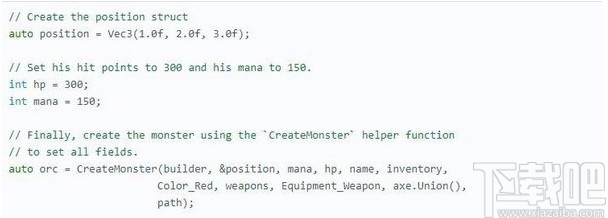
现在,让我们创建我们的怪物orc。为此orc,让他red发怒,定位于(1.0, 2.0, 3.0),并给他大量的生命值300。我们可以给他一个向量的武器(我们Sword和Axe以前)。在这种情况下,我们将为他配备Axe,因为它是两者中功能最强大的。最后,让我们用一些潜在的宝藏来填补他的库存,一旦他被击败,这些宝藏就可以被拿走。
在序列化怪物之前,我们需要首先序列化包含在其中的所有对象,即,我们使用深度优先的预遍历序列化数据树。通常在任何树形结构上都很容易做到这一点。

我们序列化了两个内置数据类型(string和vector),并捕获了它们的返回值。这些值是序列化数据中的偏移量,指示它们的存储位置,以便在向怪物添加字段时可以在下面引用它们。
注意:要创建一个vector嵌套对象(例如tables,strings或other vector),请将其偏移量收集到一个临时数据结构中,然后创建一个vector包含其偏移量的附加对象。
如果不是从一个现有的数组创建向量,而是逐个序列化元素,请注意,这是相反的顺序,因为缓冲区是从头开始构建的。
例如,看一下Weapon我们先前创建的两个(Sword和Axe)。它们都是FlatBuffer table,它们的偏移量现在存储在内存中。因此,我们可以创建一个FlatBuffervector来包含这些偏移量。

请注意,还有其他的便利重载CreateVector,它允许您处理不在a中的数据,std::vector或者允许您通过调用lambda来生成元素。对于的常见情况,std::vector也有CreateVectorOfStrings。
请注意,结构的向量与表的序列化方式不同,因为结构以内联方式存储在向量中。例如,为path上面的字段创建一个向量:

现在我们已经序列化了兽人的非标量组件,因此我们可以序列化怪物本身:

如果您不想在a中设置每个字段table,则可以更方便地手动设置怪物的每个字段,而不是调用CreateMonster()。以下代码段在功能上等同于上面的代码,但提供了更多的灵活性。

在完成序列化之前,让我们快速看一下FlatBuffer union Equipped。每个FlatBuffer都有两部分union。第一个_type是生成的隐藏字段,用于保存所table引用的类型union。这使您可以在运行时知道要转换为哪种类型。其次是union的数据。
在我们的示例中,我们添加到的最后两件事Monster是Equipped Type和Equipped本身。
这是这些行的重复,以帮助更清楚地突出显示它们:

创建缓冲区后,orc变量中的数据根将具有偏移量,因此可以通过调用适当的finish方法来完成缓冲区。

现在可以准备将缓冲区存储在某个位置,通过网络发送,进行压缩或进行任何其他操作。您可以这样访问缓冲区:

CIMCO Edit 其他软件276.25 MB7.5 简体中文版
详情CKplayer网页播放器 其他软件336 KB6.6 免费版
详情WordPress 其他软件6.7 MB4.1 英文版
详情Discuz论坛 其他软件4.05 MB官方版
详情Guns后台管理系统 其他软件12.5 MBv7.0.3 官方版
详情狂雨小说cms 其他软件7.8 MBv1.3.2 官方版
详情Slidev(开发幻灯片展示) 其他软件8.52 MBv0.10.2 官方版
详情魔众短链接系统 其他软件27.5 MBv2.0.0 官方版
详情易语言资源网源码下载工具 其他软件1.51 MBv1.0 免费版
详情W5 SOAR(自动化响应平台) 其他软件6.8 MBv0.4 官方版
详情魔众文档管理系统 其他软件28.8 MBv3.0.0 官方版
详情Milvus(矢量数据库) 其他软件6.0 MBv1.1.0 官方版
详情FlatBuffers(序列化库) 其他软件1.95 MBv2.0.0 官方版
详情Wendasns(问答社区系统) 其他软件7.8 MBv1.1.5 官方版
详情DM企业建站系统 其他软件14.0 MBv2021.5a 官方版
详情Ember.js(JavaScript框架) 其他软件1.66 MBv3.27.0 官方版
详情Exifr(EXIF读取库) 其他软件42.1 MBv7.0.0 官方版
详情RavenDB数据库 其他软件64.5 MBv5.1.7 官方版
详情iWebShop(开源商城系统) 其他软件11.5 MBv5.9.210101 官方版
详情OElove(婚恋交友系统) 其他软件28.7 MBv8.1 官方版
详情点击查看更多
ThinkSNS 其他软件20 MB4.6.1 免费版
详情CKplayer网页播放器 其他软件336 KB6.6 免费版
详情vqqq.com带20000数据库的笑话程序 其他软件300 KB2.0 官方版
详情EXE文件加口令源代码 其他软件799 KB3.0 官方版
详情PPTV网络电视系统 其他软件1.27 MB4.0.1.0 官方版
详情建站专家网站建设系统 其他软件20.02 MB1.0.4.1819 官方版
详情Turbo C 2.0库函数速查 其他软件71 KB1.0 官方版
详情中国联通SGIP1.2短消息网关客户端程序 其他软件54 KB1.37 官方版
详情伤感文学CMS文章发布系统 其他软件4.11 MB2.0 官方版
详情娱乐先锋论坛 其他软件1.31 MB5.3 官方版
详情笔试考试源代码 其他软件1.17 MB1.0.0 官方版
详情Deluge For Linux 其他软件2.79 MB1.0.0 官方版
详情幻影留言版(ASP多用户版) 其他软件567 KB5.30 官方版
详情GeniusBBS 其他软件475 KB1.1 官方版
详情上机考试源代码 其他软件1.01 MB1.0.0 官方版
详情vqqq.com在线网页编辑asp源码 其他软件22 KB1.0.0 官方版
详情CIMCO Edit 其他软件276.25 MB7.5 简体中文版
详情狐狗网页源代码显示器 其他软件434 KBBuild1214 官方版
详情农业企业网站模板中英繁企业网站管理系统源码 其他软件2.18 MB2010 官方版
详情vqqq.com多用户ip统计asp源码 其他软件134 KB1.0.0 官方版
详情点击查看更多
明星三缺一手机单机版 休闲益智61.5MBv7.2.0
详情贪玩娱乐苹果官方下载 休闲益智0MBv7.2.0
详情琼崖海南麻将15app下载 休闲益智61.5MBv7.2.0
详情狂暴捕鱼官网有330.3版本官方 休闲益智61.5MBv7.2.0
详情欢乐拼三张单机版2025 休闲益智61.5MBv7.2.0
详情彩民之家44666 生活服务68.2MBv1.7.1
详情777水果机免费单机版 休闲益智0MBv1.0
详情狂暴捕鱼官网504.1 休闲益智61.5MBv7.2.0
详情王道棋牌官网最新版 休闲益智61.5MBv7.2.0
详情炸金花下载官方下载 休闲益智61.5MBv7.2.0
详情888彩票网 生活服务33.2MBv9.9.9
详情森林舞会飞禽走兽 休闲益智0MBv1.0
详情天天炸翻天单机版 休闲益智61.5MBv7.2.0
详情一木棋牌蓝色旧版老版本2017年 休闲益智61.5MBv7.2.0
详情老式水果机单机版 休闲益智0MBv1.0
详情角落棋牌官方网站 休闲益智61.5MBv7.2.0
详情琼星海南麻将官方下载安装2024 休闲益智61.5MBv7.2.0
详情王者棋牌cc老版本 休闲益智61.5MBv7.2.0
详情波克城市棋牌 休闲益智61.5MBv7.2.0
详情牛牛下载金币版苹果 休闲益智61.5MBv7.2.0
详情点击查看更多




































